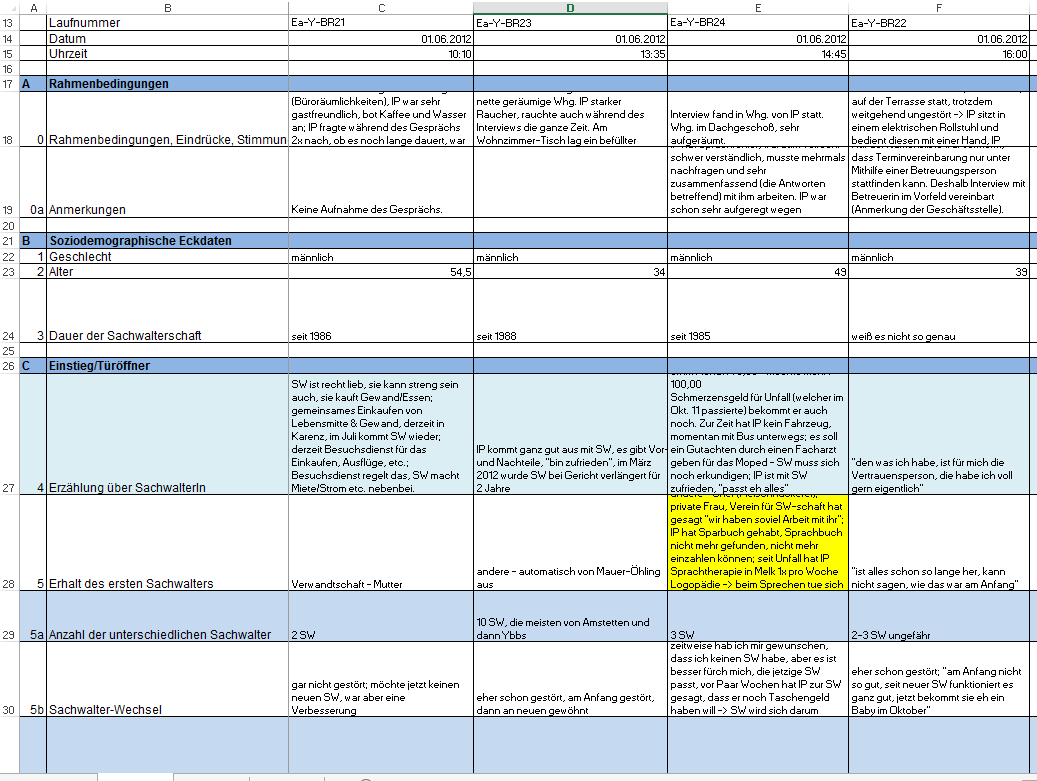
Abbildung 1: Ausschnitt einer Auswertungsmatrix
soziales_kapital
wissenschaftliches journal österreichischer fachhochschul-studiengänge soziale arbeit
Nr. 18 (2017) / Rubrik "Sozialarbeitswissenschaft" / Standort St. Pölten
Printversion: http://www.soziales-kapital.at/index.php/sozialeskapital/article/viewFile/527/947.pdf
Katharina Auer-Voigtländer & Tom Schmid:
1. Vorbemerkung
Die strukturgeleitete Textanalyse ist eine Methode zur Auswertung qualitativen Datenmaterials und dient der verstehenden Interpretation von strukturierten Interviews sowie divergentem strukturierten qualitativen Datenmaterial. Dieses Auswertungsverfahren eignet sich vor allem für eben jenes strukturierte qualitative Datenmaterial, welches in einer hohen Quantität vorliegt, da es bei diesem Auswertungsverfahren (unter anderem) um die Reduktion des Datenmaterials geht.
Da das von uns entwickelte Auswertungstool, die „Auswertungsmatrix“, der hier beschriebenen Auswertungsmethode auf dem Leitfaden des zum Einsatz kommenden Erhebungsinstruments (z. B. Leitfaden für Interviews oder Beobachtungen) aufbaut, eignet es sich im Wesentlichen für hypothesenabarbeitendes Vorgehen, denn die Erstellung eines Leitfadens als Erhebungsinstrument benötigt in der Regel als Basis klare, forschungsleitende Hypothesen. Für ein hypothesengenerierendes Arbeiten (vgl. Strauss 1998) ist die hier vorgeschlagene Methode nicht geeignet. Bei einem hypothesengenerierenden Vorgehen wird vorwiegend mit hermeneutischen Methoden der Textanalyse zu arbeiten sein.
Bei der Arbeit mit Interviews oder Beobachtungen stellt sich immer wieder die Frage, wie sie im Sinn des Forschungsvorhabens sinnvoll ausgewertet werden sollen. Dazu bietet die Literatur eine Fülle von Angeboten (vgl. dazu Atteslander 2008, Bohnsack 2008, Bortz/Döring 1995, Dittmar 2004, Flick 2009, Froschauer/Lueger 2003, Lamnek 2010, Lueger 2010, Mayring 2002, Strauss/Corbin 1996 u.v.m.). Gemeinsam ist diesen Angeboten jedoch, dass sie vor allem darauf ausgelegt sind, mit einer mehr oder weniger geringen Anzahl an Interviews bzw. deren Transkripten zu arbeiten. Natürlich werden bei hypothesengenerierenden Verfahren keine nummerischen Grenzen gesetzt. Vielmehr erfolgt die Datenerhebung und -auswertung in einem zirkulären Prozess, der sich an der theoretischen Sättigung der untersuchten Phänomene orientiert (vgl. dazu bspw. Strauss/Corbin 1996). In der Praxis der empirischen Sozialforschung, sei es für ein Forschungsprojekt oder im Zuge einer wissenschaftlichen Qualifikationsarbeit, sind wir meist auf ein gewisses Maß an Datenquellen beschränkt, wenn es um eine sinnvolle (und ökonomische) Bearbeitung dieser Daten geht – auch wenn der jeweilige Forschungsgegenstand und das damit einhergehende Forschungsinteresse zu einem anderen Vorgehen auffordern würden. Häufig ist in der Forschungspraxis nicht die Datenerhebung, sondern vielmehr die Auswertung der Daten sowie die vorbereitende Transkription der Engpass, der zu einer Datenreduktion führt. Die Transkription von Interviews stellt bei den meisten gängigen Auswertungsverfahren einen wichtigen Teil der Datenauswertung dar und ist in seiner Akribie (vollständige Wortlaut-Transkription) für bestimmte – meist hypothesengenerierende – Auswertungsmethoden notwendig und sinnvoll.
Das hier vorgestellte Auswertungsverfahren wählt stattdessen ein anderes Auswertungsformat, ist aber nur für strukturierte (in der Regel leitfadengesteuerte) Erhebungen, respektive hypothesenabarbeitende Forschungsstrategien/ Forschungsfragen sinnvoll. Im Zuge der hier vorgestellten strukturgeleiteten Textanalyse ist es nicht notwendig, vollständige Wortlaut-Transkripte anzufertigen. Es genügti, bei der Aufbereitung von Interviews für die Datenauswertung zu differenzieren und nur dort in die Tiefe zu gehen, d. h. vollständig zu transkribieren, wo dies für die Datenauswertung notwendig und sinnvoll ist. An allen anderen Stellen des Textes ist eine weniger aufwändige Transkription beziehungsweise Aufbereitungsmethode zu verwenden. Die Auswertungsstruktur ist durch die Vorstrukturierung des Erhebungsinstruments (Leitfaden) ja bereits (deduktiv) vorgegeben.
Allerdings ist die Entscheidung für die hier dargestellte Auswertungsmethode nicht willkürlich zu setzen, sondern regelgebunden. Ausgehend von der jeweiligen Forschungsfrage ist zu klären, ob die gegenständliche Untersuchung nur an den manifesten Inhalten des Datenmaterials (den Aussagen von Interviewpartner*innen) interessiert ist, oder auch an dem latenten Bedeutungsgehalt dieser. Besteht Interesse an dem latenten Bedeutungsgehalt, also an den „Aussagen hinter den Aussagen“, wird man auch weiterhin nicht umhinkommen, die Interviews sehr sorgfältig zu transkribieren und das erhobene Datenmaterial dann mit hermeneutischen Methoden der Textanalyse auszuwerten. Denn um latente, nicht sichtbare Bedeutungsinhalte erschließen zu können, kommt es auf jedes Wort, jede textliche Redundanz und letztlich auf jede Satzpause und jedes Räuspern an. Je ausführlicher und akribischer hier das Transkript vorliegt, desto besser sind die Deutungsmöglichkeiten durch die auswertenden Personen.
Anders stellt sich das hingegen dar, wenn auf Grund der Forschungsfrage das ausschließliche Interesse den manifesten Inhalten des Datenmaterials gilt. Hier besteht keine Notwendigkeit für ein ausführliches Transkript, denn hier liegt das Interesse hauptsächlich auf dem Wissenstransfer der manifesten Inhalte. Mit der hier vorgestellten Auswertungsmethode können diese manifesten Inhalte zeiteffizient und sinnvoll erfasst werden. Dabei ermöglicht das Vorgehen der strukturgeleiteten Textanalyse jene Ressourcen zu sparen, die dann zulässt, eine höhere Zahl an Datenquellen/Interviews zu bearbeiten. Da sich die von uns vorgestellte Methode der strukturgeleiteten Textanalyse für alle Formen von Interviews, die auf Grundlage eines Leitfadens erstellt werden, eignet, kann damit insbesondere bei Delphibefragungen oder bei Typisierungen (siehe Bohnsack 2013, Nentwig-Gesemann 2013) mit einer größeren Menge von Interviews rationell gearbeitet werden.
2. Die Methode der strukturgeleiteten Textanalyse
Die strukturgeleitete Textanalyse folgt einem mehrgliedrigen regelgeleiteten Prozess, der nun näher beschrieben wird und eine bildliche Veranschaulichung des Umgangs mit dem Auswertungstool bietet.
Eine der Grundvoraussetzungen für die Anwendung der strukturgeleiteten Textanalyse ist (neben Forschungsstrategie und dem zu Folge der Sinnhaftigkeit der Auswertungsmethode für die Beantwortung der Forschungsfrage) ein zum Einsatz kommendes strukturiertes Erhebungsinstrument, ein Erhebungsleitfaden. Das vorstrukturierte Erhebungsinstrument bietet die Grundlage für die Erstellung des Auswertungstools, der so genannten „Auswertungsmatrix“. In einem ersten Schritt des Auswertungsprozesses geht es um die Reduktion der Datenmenge. Im Konkreten bedeutet dies, die für die Forschungsfrage relevanten Aspekte der erhobenen Daten zu identifizieren und aufzubereiten. Hierbei folgt man in der Regel der Strukturierung des Datenerhebungsinstruments. Wenn es sich bei dem Erhebungsinstrument beispielsweise um einen Interviewleitfaden handelt, wird man sich an den Fragen des Interviewleitfadens orientieren1. Bei strukturierten Beobachtungen würde die Orientierung anhand des Beobachtungsleitfadens erfolgen usw.
Demzufolge bedient sich die Datenauswertung mittels strukturgeleiteter Textanalyse einer deduktiven Kategorienanwendung. Dies bedeutet, dass das Kategoriensystem bereits durch die Strukturierung der Datenerhebung (eben durch den Erhebungsleitfaden) vorgegeben ist. Anhand des Erhebungsinstruments (Interviewleitfaden, Beobachtungsleitfaden, …) wird das Auswertungstool (die Auswertungsmatrix) erstellt (siehe Abbildung 1). Zur Erstellung der Auswertungsmatrix empfehlen wir ein Vorgehen mittels einer Microsoft-Excel-Tabelle, wobei grundsätzlich mit allen Arten von Tabellen gearbeitet werden kann. Zur Erstellung des Auswertungstools nimmt man sich das Erhebungsinstrument zur Hand und setzt in die erste Spalte jeder Zeile der Tabelle eine Fragestellung oder einen Themenkomplex des Erhebungsinstruments ein.
Ein Beispiel:
Nehmen wir an, Sie beschäftigen sich im Rahmen Ihres Projekts mit der Frage nach der Zufriedenheit von besachwalterten Personen mit ihrem*ihrer Sachwalter*in. Zur Datenerhebung haben Sie leitfadengestützte Interviews geplant. Laut Ihrem Interviewleitfaden beginnen Sie Ihr Interview (nach dem Einstieg und dem sogenannten Türöffner) mit der Bitte, dass Ihr*e Interviewpartner*in etwas über ihre*n Sachwalter*in erzählt („Erzählen Sie mir bitte ein bisschen etwas über Ihren Sachwalter*Ihre Sachwalterin!“). Ihre zweite Frage beschäftigt sich mit der Sachwalterschaftsanregung („Wie haben Sie Ihren ersten Sachwalter*Ihre erste Sachwalterin bekommen?“). Frage drei zielt auf das Erfassen der Anzahl der Sachwalter*innen ab (Wie viele verschiedene Sachwalter*innen hatten Sie schon?“) usw. Für die Erstellung der Auswertungsmatrix ziehen wir diesen Interviewleitfaden heran und setzen in die erste inhaltliche Spalte (ausgenommen der Nummerierungen) das erste Thema/die erste Fragestellung des Erhebungsleitfadens ein. In der nachfolgenden Abbildung ergeben sich so folgende Themen/Fragestellungen:
| Interview 1 | Interview 2 | Interview … | Zeilenaussage | Memos | ||
| 0 | Anmerkungen zum Interview und der Interviewsituation | |||||
| 1 | Erzählung über Sachwalter*in | |||||
| 2 | Erhalt des Sachwalters*der Sachwalterin | |||||
| 3 | Anzahl der Sachwalter*innen |
So ergibt sich für jede Zeile eine Fragestellung bzw. ein Thema als Ergebniskategorie. Vor der ersten Ergebniskategorie-Zeile können Sie eine Zeile mit „Anmerkungen zum Interview und der Interviewsituation“ einfügen in der sie für sie relevante Daten (bspw. Erhebungssituation, Erhebungsdauer, Datum der Erhebung etc.) einfügen. Jede Spalte der Tabelle sollte jeweils einem Interview bzw. einem Erhebungsdokument entsprechen. Der Tabelle werden so viele Spalten hinzugefügt, wie Erhebungs-Dokumente auszuwerten sind.
Angeschlossen werden nach allen notwendigen Spalten für die auszuwertenden Dokumente, jeweils eine Spalte für die zusammenfassende Auswertung (pro Frage) sowie eine Spalte für erste Kommentare/Memos des auswertenden Teams.
Für den Auswertungsprozess werden nun keine Interviewtranskripte in klassischer Form angelegt, sondern das (in der Regel auf Tonträgern) vorhandene Material wird bereits zusammengefasst und auf den wesentlichen Inhalt reduziert und in klare Sinneinheiten in das jeweils thematisch passende Feld der Auswertungsmatrix eingetragen. Wurde beispielweise eine Zeile der Auswertungsmatrix dem Thema „Motive für eine ehrenamtliche Tätigkeit“ zugeteilt, dann werden alle Aussagen zu diesem Thema in die entsprechende Tabellenzeile eingetragen. Relevant ist hierbei vor allem, längere Aussagen bzw. Textpassagen auf ihre Quintessenz zu reduzieren. Der eingetragene Text soll eine essenzielle Zusammenfassung der jeweiligen Aussage bzw. des jeweiligen kategorialen Datenmaterials beinhalten.
Nachdem alle Datenerhebungen durchgeführt und die entsprechend bearbeiteten Daten in die Auswertungsmatrix eingetragen wurden, kann mit dem nächsten Schritt der Datenauswertung begonnen werden. Dazu werden (wenn nicht bereits erstellt) in der Tabelle üblicherweise am rechten Ende der Auswertungsmatrix zwei neue Spalten gebildet, die der Erkennbarkeit wegen verschiedenfärbig hinterlegt werden können. In der ersten der am Ende befindlichen Spalten werden die Ergebnisse der jeweiligen Kategorie/des jeweiligen Themas zusammenfassend eingetragen. Diesen zusammenfassenden Text nennen wir Zeilenaussage. In der nächsten Spalte werden kategorienbezogene Auffälligkeiten und Anmerkungen notiert. Vermerkt haben wir diese Spalte als Memo-Spalte. Das Augenmerk wird dabei insbesondere darauf gerichtet, wo die gewonnenen und eingetragenen Aussagen sowie Textpassagen im Widerspruch zu dem anderen Datenmaterial und/oder der themenrelevanten verwendeten Literatur stehen, beziehungsweise ein für das Forschungsteam unerwartetes Ergebnis zeigen. Die Memos können weiters auch Anmerkungen und/oder Interpretationsversuche der auswertenden Personen beinhalten. Es macht Sinn, alles, was Ihnen im Auswertungsprozess auffällt, in dieser Spalte zu notieren. Es empfiehlt sich, die Datenauswertung mittels strukturgeleiteter Textanalyse in einem Forschungsteam durchzuführen, um subjektiven (Be-)Wertungen möglichst entgegenzuwirken.
Wie bereits angedeutet, eignet sich die strukturgeleitete Textanalyse vor allem für solche Forschungsprojekte, wo es um die effiziente Verarbeitung größerer, bereits vorstrukturierter (Interview-)Daten geht und sich das Forschungsinteresse vor allem auf den manifesten Inhalt des Datenmaterials richtet. Latente Inhalte können am Rande auch erfasst werden, stehen im Prozess des gegenständlichen Auswertungsverfahrens jedoch nicht im Zentrum des Forschungsinteresses. Die strukturgeleitete Textanalyse eignet sich daher besonders gut für die Auswertung leitfadengestützter Befragungen von Stakeholdern und/oder so genannten Expert*innen sowie für die Auswertung von Delphibefragungen. Durch die strukturierte und themen- sowie datenquellenbezogene Auswertung des Datenmaterials lassen sich Typen gut systematisiert und übersichtlich bilden.
2.1 Der Auswertungsprozess im Detail
2.1.1 Auswertungsschritt 1: Zeilen- und Kategorienaussage
Die Auswertung der – mit Datenmaterial angereicherten – Auswertungsmatrix erfolgt anhand der untersuchungsleitenden Fragestellungen bzw. des vorhandenen Kategoriensystems. Jede (vor-)definierte Kategorie – in der Regel je eine Frage bzw. ein Thema des Erhebungsinstruments – beinhaltet alle Aussagen des gesamten Datenmaterials, welche dieser zugeordnet werden konnten. Sind die Zeilenkategorien mit dem jeweiligen Datenmaterial angereichert, werden diese jeweils Kategorienbezogen durchgearbeitet. Das Bearbeiten jeder Kategorie führt zu einer Zeilen- bzw. Kategorienaussage. Diese erfasst den manifesten Inhalt des gesamten erhobenen Datenmaterials der jeweiligen Kategorie bzw. des jeweiligen Themas aus dem Material.
2.1.2 Auswertungsschritt 2: Erfassung von Auffälligkeiten und Memos
In einem weiteren Schritt werden in der letzten Spalte Auffälligkeiten, die sich bezogen auf die forschungsleitende/n Fragestellung/en in der jeweiligen Kategorie ergeben, identifiziert. Diese können sich beispielweise auf Aussagen beziehen, die im restlichen Datenmaterial nicht oder ausschließlich diametral zu finden sind. Diese Auffälligkeiten werden in der dafür vorgesehenen Spalte für kategorienbezogene Memos beziehungsweise Kategorie-Notizen vermerkt. Neben dem Vermerk von Auffälligkeiten dienen die Kategorien-Memos der Erfassung von Kommentaren zu den manifesten Inhalten der Zeilenaussage. Die Memos machen Abweichungen vom Erwarteten deutlich (wo das Forscher*innenteam auf Grund seiner Kenntnis oder der Fachliteratur andere Antworten erwartet hätte) und bieten Raum für Interpretationen vermuteter latenter Inhalte. Diese beiden Auswertungsschritte werden Zeile für Zeile bzw. Kategorie für Kategorie entlang der gesamten Auswertungsmatrix vorgenommen. Der hier, in den Spalten ‚Zeilen- und Kategorienaussage‘ und ‚Kategorien-Memo‘, ermittelte Inhalt bildet den Kern des Narrativs der Berichterstattung. Folgende zwei Leifragen sind hier vorstehend: (1) Welche Zeilen- bzw. Kategorienaussagen sind hervorgetreten? und (2) Was ist auffällig?
2.1.3 Kooperative Datenauswertung und Zitation
Es ist sinnvoll und ratsam, die eben genannten Auswertungsschritte mittels eines durchgängig kooperativen Prozesses im (gesamten) Forschungsteam oder bei Einzelvorhaben gemeinsam mit einer kleinen forschungsunterstützenden Gruppe durchzuführen. Bei Einzelauswertungen ist die Gefahr gegeben, relevante Zusammenhänge nicht zu erkennen oder zu übersehen. Im Fall einer Einzelauswertung wird daher empfohlen, das Datenmaterial mindestens einer mehrfachen Durchsicht sowie einer abschließenden kooperativen Betrachtung zu unterziehen.
Das Datenmaterial wird im Rahmen der strukturgeleiteten Textanalyse nach einem Code, der sich aus der Zeilen- und Spaltenzahl der Auswertungsmatrix zusammensetzt, zitiert und ist so in der Auswertungsmatrix (und damit auch im originalen Tonträger) leicht aufzufinden. Ein Beispiel hierfür könnte bei Betrachtung der nachstehenden Abbildung 1 wie folgt aussehen: C27 – ‚C‘ steht für das betreffende Interview (hier Interview Ea-Y-BR21) und ‚27‘ für den Kategorienkomplex (hier ‚Erzählung über den Sachwalter‘).
3. Die Auswertungsmatrix: Ein Beispiel
Anbei haben wir zur Veranschaulichung der Arbeit mit der Auswertungsmatrix ein Beispiel aus einem bereits abgeschlossenen drittmittelfinanzierten Projekt dargestellt. Das Projekt beschäftigte sich mit der Erhebung der Zufriedenheit von Klient*innen mit der Sachwalterschaft. Die Zielsetzung des Projekts umfasste ein systematisch eingeholtes Feedback von Klienten und Klientinnen der ständigen Sachwalterschaft in Bezug auf (erlebte) Vertretungs- und Beratungstätigkeiten seitens der betreffenden Sachwalter*innen. Insgesamt wurden im Projektverlauf 67 Interviews mit Klientinnen und Klienten der ständigen Sachwalterschaft geführt. (vgl. Vyslouzil et al. 2012, Auer/Vyslouzil 2013) Da das gegenständliche Forschungsvorhaben vorwiegend auf die manifesten Inhalte, d. h. ein systematisch eingeholtes Feedback ausgerichtet war und das Datenmaterial sowohl in vorstrukturierter Form als auch in einer großen Anzahl vorlag, wurde das Datenmaterial mittels der strukturgeleiteten Textanalyse ausgewertet.
Untenstehend sieht man das Visualisierungsbeispiel der im Projektverlauf entstandenen Auswertungsmatrix.
Abbildung 1: Ausschnitt einer Auswertungsmatrix
Abbildung 1 visualisiert den ersten Ausschnitt einer Auswertungsmatrix. In Spalte B finden sich neben einiger Eckdaten zum Interview (Zeile 13-19) und zur Interviewperson (Zeile 22-24) der Beginn des eingetragenen Kategoriensystems, welches durch den Interview-Leitfaden bereits vorstrukturiert ist (ab Zeile 26). Spalten C, D und folgende veranschaulichen das jeweilige themen- bzw. kategorienspezifisch eingetragene Datenmaterial.
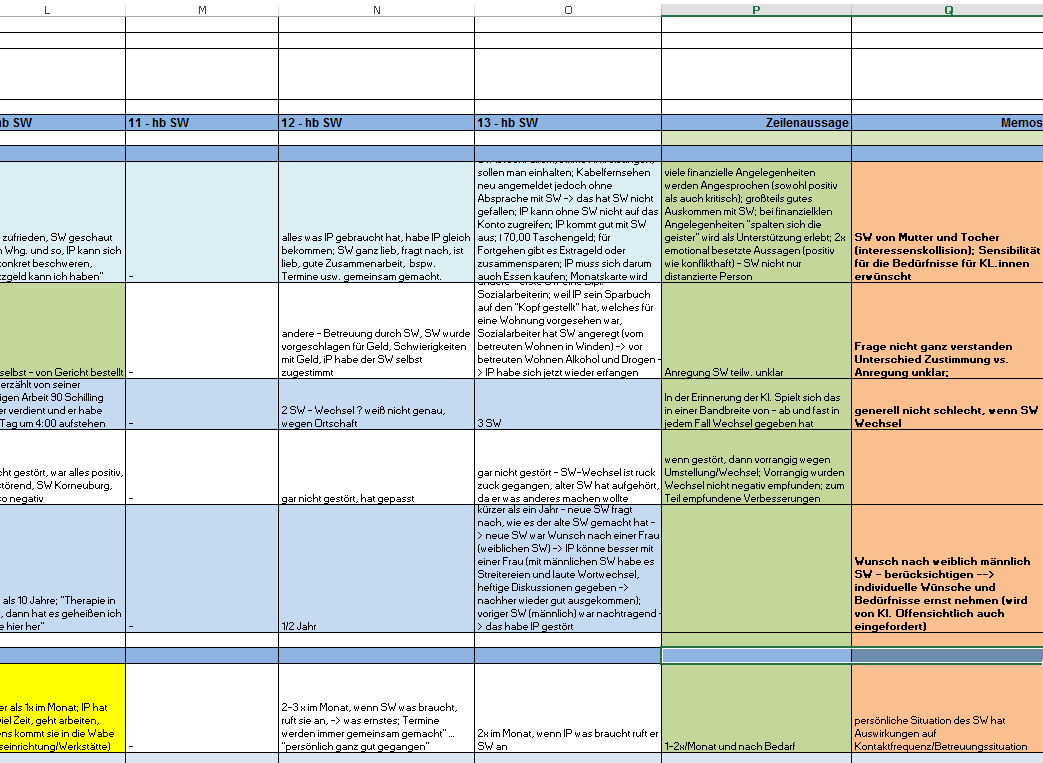
Abbildung 2: Zeilenaussagen und Memos in der Auswertungsmatrix
Abbildung 2 verdeutlicht den Bereich der Auswertungsmatrix, in dem die Auswertungsergebnisse in Form der Zeilenaussagen und Memos eingetragen werden. Hier erkennt man in Spalte L bis O Datenmaterial, welches bereits in der Auswertungsmatrix eingetragen wurde. Spalten P und Q verbildlichen die Zeilen- bzw. Kategorienaussagen (P) sowie die Kategorien-Notizen bzw. Memos (Q).
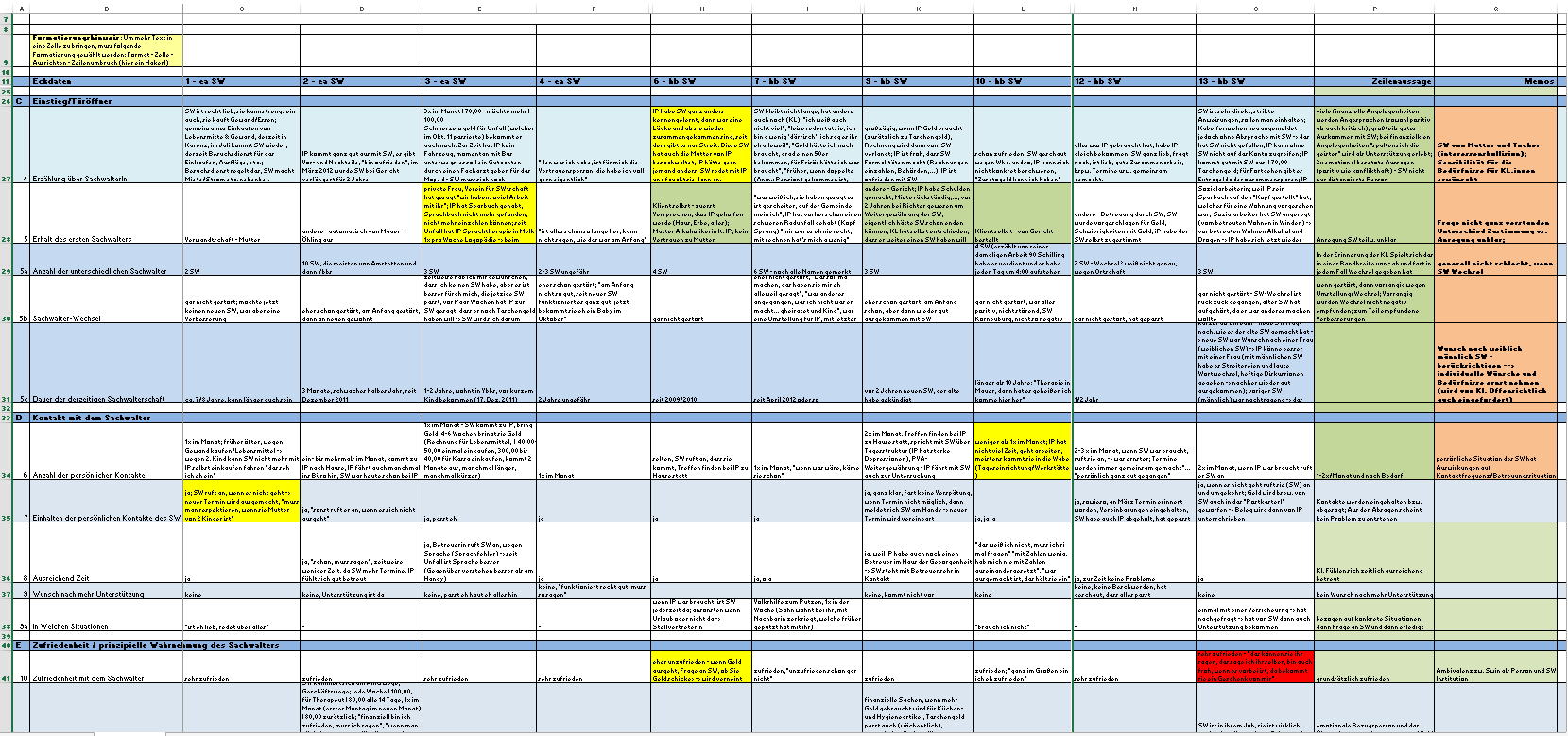
Abbildung 3: Längsschnitt einer Auswertungsmatrix
Abbildung 3 bietet einen Überblick über den Längsschnitt einer Auswertungsmatrix mit zehn eingetragenen Interviews inkl. Zeilenaussagen und Memos. Es empfiehlt sich Interviewpassagen, von denen man bereits in der Auswertung erkennt, dass sie möglicherweise als direkte Zitate in das Narrativ der Arbeit einfließen können, in der Matrix farblich zu markieren. Die hier gelb markierten Passagen visualisieren sogenannte Ausreißer, d. h. Aussagen, die ausschließlich in einem Interview vorkommen. Die grün hinterlegten Aussagen markieren jene Inhalte, die keine nachvollziehbaren Aussagen beinhalten, beispielsweise auf Grund von Aussagen, die nach den in Österreich gültigen rechtlichen Vorschriften unrealistisch bzw. nicht möglich sind. Die rote Markierung wurde zur Verdeutlichung einer Aussage verwendet, die einen positiven Pol hervorhebt.
4. Ein praktisches Anwendungsbeispiel
In einer Untersuchung über die Rolle des „Hausarztes in der Versorgungskette“ (Auer et al. 2011: 475ff) sollte die typische Haltung von Patient*innen zu ihrer hausärztlichen Versorgung erhoben werden, um damit auch die Frage abzuklären, ob es in Österreich eine (gewisse) Zustimmung für ein „Gatekeepersystem“ (Nachfragesteuerung durch eine verpflichtende Anlaufstelle beim Hausarzt/der Hausärztin) geben könnte. Es wurde ein mehrstufiges Vorgehen gewählt. Neben einer Auswertung der aktuellen Literatur zum Thema folgte ein zweiter hermeneutischer Schritt, in dem narrative Interviews mit Patient*innen geführt wurden. Die Interviewpartner*innen wurden mit Hilfe der Österreichischen Sozialversicherung angeschrieben und um ein Interview gebeten. Einziges Auswahlkriterium, nachdem angeschrieben wurde, waren mehr als acht ärztliche Kontakte im vergangenen Jahr. In diesem Modul des Forschungsprozesses ging es darum, latente Inhalte der befragten Patient*innen zu erfassen, weswegen die Daten mittels unstrukturierten narrativen Interviews erhoben wurden. Aufgrund des Erkenntnisinteresses und der Erhebungsart wurden die Interviews anschließend vollständig transkribiert und hermeneutisch ausgewertet. Aus dem Material konnten hermeneutisch fünf typische Verhaltensformen extrahiert werden (vgl. dazu auch Nentwig-Gesemann 2013). Diese fünf Typen wurden aus dem Datenmaterial heraus ausführlich beschrieben.
In einem zweiten Untersuchungsschritt wurden niedergelassene praktische Ärzt*innen (in Wien und in einer ländlichen Region Österreichs) befragt, um die gewonnene Typisierung anhand ihrer praktischen Erfahrung verifizieren (oder verwerfen) zu können. Demnach bezog sich das Erkenntnisinteresse dieses Forschungsmoduls auf eine deduktive Datengewinnung. Dazu wurde anhand der Merkmale der fünf Typen ein Leitfaden gebildet, anhand dessen die Interviews strukturiert wurden. Die Interviews wurden anhand eines Interview-Leitfadens durchgeführt. Für die Datenauswertung wurde unter Zugrundelegung des Leitfadens eine Auswertungsmatrix gebildet und mit den verdichteten Aussagen aus den Interviews gefüllt. Die gefüllte Matrix wurde in einer gemeinsamen Sitzung des Erhebungsteams ausgewertet und kommentiert.
Die aus den narrativen Interviews mit Patient*innen gewonnenen Hypothesen konnten durch die strukturierten Interviews mit Ärzt*innen weitgehend bestätigt werden. Die Ergebnisse wurden in einem Forschungsbericht (vgl. Auer/Hengl/Schmid 2013) und einer wissenschaftlichen Publikation in der Fachzeitschrift „Soziale Sicherheit“ (vgl. Auer et al. 2011) publiziert.
5. Erfahrungen mit der Methode
Wir arbeiten sowohl in der sozialwissenschaftlichen Forschung als auch in der Lehre seit einigen Jahren mit dieser Methode und haben durchwegs sehr gute Erfahrungen damit gemacht. Wie bereits beschrieben, ermöglicht diese Methode eine effiziente Auswertung von umfassendem Datenmaterial und daher eine durchführbare Erhöhung der Anzahl des möglichen auszuwertenden Datenmaterials. Diese Methode erleichtert unserer Erfahrung nach in der Auswertungsphase, insbesondere wenn diese im Team erfolgt, eine breite Erfassung aller manifesten Inhalte und vermindert die Gefahr, einzelne Aussagen zu übersehen. Zur Erhöhung der Übersichtlichkeit wird der Prozess der Datenauswertung üblicherweise in einem Raum durchgeführt, indem die Auswertungsmatrix mit einem Beamer an eine Wand projiziert wird oder mittels großem Bildschirm übersichtlich dargestellt wird, um gemeinsam analysiert werden zu können. Wenn solche infrastrukturellen Voraussetzungen nicht gegeben sind, kann alternativ natürlich parallel an mehreren Computern gearbeitet werden.
Die Ergebnisse des Auswertungsprozesses werden sinnvollerweise gleich in die Auswertungsmatrix eingetragen und können, wenn technisch möglich, vom gesamten Team in einem gemeinsamen Bild verfolgt und kommentiert werden.
Wir haben die Erfahrung gemacht, dass auch Studierende die strukturgeleitete Textanalyse gerne zur Auswertung ihres strukturierten Datenmaterials nutzen. Insbesondere bei Delphibefragungen, wo es – im Kontext einer Thesis – darauf ankommt, drei (oder mehr) Wellen von Interviews in jeweils relativ knapper Zeit durchzuführen und auszuwerten, um die durch den Abgabetermin gesetzte Frist nicht zu sprengen, kommt die strukturgeleitete Textanalyse gerne zum Einsatz. Die Rückmeldung von Studierenden zeigt, dass viele Studierende es als methodischen Vorteil und als Effizienzgewinn sehen, strukturierte Interviews nicht (mehr) mühsam wörtlich transkribieren zu müssen und geben immer wieder an, sich auch in der Auswertungsphase mit Hilfe der Auswertungsmatrix gut in ihrem Datenmaterial zurecht zu finden. Das Gleiche gilt auch in der Auftragsforschung, wo die (teure) Arbeitsphase der wortwörtlichen Transkripte2 wegfällt und daher günstiger angeboten werden kann.
6. Zusammenfassung
Die strukturgeleitete Textanalyse stellt ein (stark) regelgeleitetes Verfahren zur Erfassung von vor allem manifesten Inhalten dar und erscheint geeignet für Material, das durch die strukturierte (leitfadengestützte) Datenerhebung bereits einen hohen Grad an Systematisierung aufweist. Durch die Abfolge einzelner genau definierter Schritte des Verfahrens ist eine effiziente Darstellung und Kommentierung – vorwiegend manifester – Inhalte größerer Datenmengen möglich. Als Zusatznutzen dieser Auswertungsmethode bietet sich gegebenenfalls ihre Verwendung zur Typisierung von Befragtengruppen oder zur Effizienzsteigerung von Delphibefragungen an.
Ziel der strukturgeleiteten Textanalyse ist es, das gesamte Datenmaterial auf seine wesentlichen manifesten Inhalte entlang der vordefinierten Kategorien zu reduzieren. Dadurch werden (die) zentrale(n) Aussagen/Erkenntnisse sowie divergierende Auffälligkeiten des Gesamtmaterials gut sichtbar.
Bei der strukturgeleiteten Textanalyse geht es jedoch auch um das Herausarbeiten bestimmter Strukturen, bezogen auf inhaltliche Aspekte, sowie darum, bestimmte Typen, die im Datenmaterial zu finden sind, herauszuarbeiten. Die Voraussetzung hierfür sind die vorab exakt vordefinierten Kategoriendimensionen (durch das strukturierte Erhebungsinstrument wie bspw. einen Interviewleitfaden), so dass bestimmte Textstellen des Datenmaterials jeweils einer bestimmten Kategorie zuordenbar sind. Diese Definitionsarbeit bzw. die Erstellung des entsprechenden Interviewleitfadens setzt in der Regel das Vorhandensein von untersuchungsleitenden Hypothesen vor Beginn der Befragung oder Beobachtung voraus. Dadurch eignet sich diese Methode auch, Aussagen, die zuvor in einem hypothesengenerierenden Prozess gewonnen wurden, hinsichtlich ihrer Schlüssigkeit und Plausibilität bei ausgewählten Stakeholder*innen beziehungsweise Expert*innen in einer zweiten Erhebungsrunde zu überprüfen.
Verweise
1 Die Struktur des Leitfadens ist ja ihrerseits wiederum aus der Logik der untersuchungsleitenden Hypothesen entstanden.
2 Achtung, dies gilt wie bereits beschrieben nicht für hypothesengenerierende Verfahren. Hier kann auf eine wortwörtliche Transkription nicht verzichtet werden.
Literatur
Atteslander, Peter (2008): Methoden der empirischen Sozialforschung. 12. Auflage, Berlin: Erich Schmidt Verlag GmbH & Co.
Auer, Katharina / Fischer, Timmo / Hengl, Stefanie / Schmid, Tom / Schauppenlehner, Mathias (2011): Fünf typische Wege ins Gesundheitssystem – die Rolle des Hausarztes in der Versorgungskette. In: Soziale Sicherheit, 10/2011, S. 470-482.
Auer, Katharina / Hengl, Stefanie / Schmid, Tom (2013): Fünf typische Wege ins das Gesundheitssystem. Die Rolle des Hausarztes in der Versorgungskette. Unveröffentlichter Endbericht, St. Pölten: Ilse Arlt Institut für Soziale Inklusionsforschung.
Auer, Katharina / Vyslouzil, Monika (2013): Zufriedenheit von KlientInnen mit der Qualität der Sachwalterschaft. In: iFamZ – Interdisziplinäre Zeitschrift für Familienrecht, 04/2013, S. 91-93.
Bohnsack, Ralf (2013): Typenbildung, Generalisierung und komparative Analyse: Grundprinzipien der dokumentarischen Methode. In: Bohnsack, Ralf / Nentwig-Gesemann, Iris / Nohl, Arnd-Michael (Hg.): Die dokumentarische Methode und ihre Auswertung. Wiesbaden: VS Verlag für Sozialwissenschaften, S. 241-257.
Bohnsack, Ralf (2008): Rekonstruktive Sozialforschung. Einführung in qualitative Methoden. Opladen: UTB Verlag.
Bortz, Jürgen / Döring, Nicola (1995): Forschungsmethoden und Evaluation. 2. Auflage, Berlin: Springer-Verlag.
Dittmar, Norbert (2004): Transkription. Ein Leitfaden mit Aufgaben für Studenten, Forscher und Laien. Wiesbaden: VS Verlag für Sozialwissenschaften.
Flick, Uwe (2009): Sozialforschung. Methoden und Anwendungen. Ein Überblick für die BA Studiengänge. Reinbek: Rowohlt Taschenbuch Verlag.
Froschauer, Ulrike / Lueger, Manfred (2003): Das qualitative Interview. Wien: UTB Verlag.
Lamnek, Siegfried (2010): Qualitative Sozialforschung. Weinheim/Basel: Beltz Verlag.
Lueger, Manfred (2010): Interpretative Sozialforschung: Die Methoden. Wien: UTB Verlag.
Mayring, Phillipp (2002): Einführung in die qualitative Sozialforschung. Weinheim/Basel: Beltz Verlag.
Nentwig-Gesemann, Iris (2013): Die Typenbildung der dokumentarischen Methode. In: Bohnsack, Ralf / Nentwig-Gesemann, Iris / Nohl, Arnd-Michael (Hg.): Die dokumentarische Methode und ihre Auswertung. Wiesbaden: VS Verlag für Sozialwissenschaften, S. 258-323.
Strauss, Anselm / Corbin, Juliet (1996): Grounded theory: Grundlagen qualitativer Sozialforschung. Weinheim: Beltz Verlag.
Strauss, Anselm (1998): Grundlagen qualitativer Sozialforschung: Datenanalyse und Theoriebildung in der empirischen soziologischen Forschung. 2. Auflage, Stuttgart: UTB Verlag.
Vyslouzil, Monika / Auer, Katharina / Holovics, Andrea / Rieder, Barbara (2012): KlientInnenzufriedenheitsanalyse des Niederösterreichischen Landesvereins für Sachwalterschaft und Bewohnervertretung. Unveröffentlichter Endbericht, St. Pölten: Ilse Alt Institut für Soziale Inklusionsforschung.
Über die AutorInnen
Katharina Auer-Voigtländer MA
|
|
Prof. (FH) Dr. Tom Schmid
|